




英雄联盟投注,英雄联盟,英雄联盟下注,LOL投注官网,英雄联盟赛事投注,英雄联盟下注,英雄联盟电竞,英雄联盟投注网站,LOL,英雄联盟赛事,LOL投注,LOL赛事下注,LOL投注网站,lol下注平台,也就是一个单独的字符串(string)或数字(numbers),比如北京这个单独的词。
第二种类型是序列(sequence),也就是若干个相关的数据按照一定顺序并列在一起,又叫做数组(array)或列表(List),比如北京,上海。
第三种类型是映射(mapping),也就是一个名/值对(Name/value),即数据有一个名称,还有一个与之相对应的值,这又称作散列(hash)或字典(dictionary),比如首都:北京。
所以在编程语言中,只要有了数组(array)和对象(object)就能够储存一切数据了。即便在存储中,mongoDB redis(string,hash,list,set,zset)支持的数据类型翻来覆去也就那几种,mongoDB除去内置的objectId() 也就这几种的数据操作,这篇博客先来说一下map里面特别的TreeMap。其实讲了map就等于讲了set了,你知道w什么吗?
简单来说map是一个一一对应的key-value的结构,key不可以重复,通过key快速索引值。
我想最基本的你应该想要构造一个可以存储key-value的数据结构,然后通过设计来达到通过key快速索引值。
我们常见的数据结构都是单结构的,如何构造对应关系的结构呢?很多人可能用过js,在js里我们可以使用这样的数组:u[website] = “知乎”。这样貌似可以把数组的类似的下标作为key,对应的值作为value。但Java毕竟不可以这样,那Java如何构造这种结构呢,你可能还想过把key-value作为一个整体,类似c++的结构体,这样我们可以在结构体里有:标记key 标记value 和一个指向下一个元素的next指针(用于遍历 malloc内存)。这样一个结构体在Java里可以用对象来代替,ok,我们需要一个这样的对象!完成了第一步。
假如我有这样一个数组,数组里保存了40亿条不重复的long型数据,我要你告诉我里面有没有8这个数 ,你要怎么做(40亿数据load到内存需要几十G内存这里只是一个假设,莫在意,有兴趣的可以看看bitmap)?
最简单粗暴的是循环判断,可以么?当然可以。但那太慢了,,,因为这么多的数据完全零散的没有规律 完全无从下手。我们都知道在数据库里有索引的概念,通过对数据表里某一个或者某几个字段建立索引可以大大加快select的速度。我们能不能借鉴一下数据库的做法呢?MySql使用的是B+Tree索引,你可以想我们需要一个树!
到此,要自己弄一个map需要一个对象来表示数据结构、一棵树用来构建索引。
那个树怎么办?所以上面的结构还不行,需要改进。就像文章头图一样,一棵树有root节点有左右子树 就像这样
但我们是TreeMap,我们可跟其他的不一样呢,人家可以有序的。好了好了,,有序又怎样,你是TreeMap那我们用红黑树(实现有序)好不啦。就酱紫。。。
所以:我们决定用红黑树的结构来处理TreeMap。这也正是jdk的实现啦!看看源码我们其实差不太多,,,
所以一切围绕TreeMap的操作,你脑子里应该是谁在这棵树的头上,谁成了谁的儿子,谁跟谁是兄弟,总之我们是一颗红黑树。
废话说了这么多,下面进入正题。那TreeMap与一致性hash到底有什么关系?要讲一致性hash就要先说hash,hash是什么------Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。百科说的也比较蛋疼,简单说hash就是寻找一种数据和存储或者其他类似的对应关系。Java里有hashcode hashset hashmap。看着都和hash有关,我们怀着探索未知的心情打开JDK Object来看下hashcode到底是怎么生成的,于是:
你妹,native的方法,本地的,我们还是naive了。看来是看不到了,,,呵呵,这时我们打开了jvm hotspot的包,下面有synchronizer.cpp这个类,里面有这样的代码(sample:
我试图看懂TMD这到底是什么意思,最后…… 请教了身边的c++同学也没法,只能看看方法的注释(注释是多么的重要)和Google了一下,Java 中Object对象hashcode()返回值是与Object对象的内存地址相关联但不等于地址的整形描述数值。Java中有很多hash算法,类似的MD5 SHA1 SHA256等 hash有各种各样的算法,如何衡量一个hash算法的优劣呢-----性能和碰撞率。如果你的算法10个数里面有两个数hash后数值一样,那还hash个蛋。自己实现hash算法不太现实,给大家安利一个:MurmurHash。高运算性能,低碰撞率,现已加入Google-guava大礼包!
上次QQzone的同学过来交流提到,他们把不同号段的数据储存在不同的机器上,以用来分散压力。假如我们有一百万个QQ号,十台机器,,如何划分呢?
最简单粗暴的方法是用QQ号直接对10求余,结果为0-9 分别对应上面的十台机器。比如QQ号为 23900 的用户在编号为0的机器 23901的用户在编号为1的机器,以此类推。那么问题来了,现在QQ用户急剧上升 由一百万涨到了五百万,显然10台机器已经无能为力了,于是我们扩充到25台。这个时候我们发现以前的数据全乱了。完蛋!只能跑路了……
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
所以在保证合理分散的情况下,我们还是是可拓展的。这就是一致性hash,一致性hash 算法都是将 value 映射到一个 32 位的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,当有数据过来按顺时针找到离他最近的一个点,这个点,就是我要的节点机器。如下图:
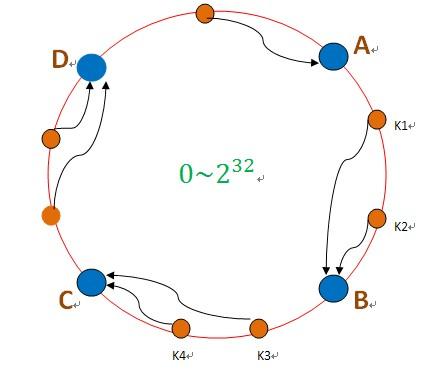
hash(192.168.128.670) ----A //根据服务器IP hash出去生成节点
这样当有新的机器加进来,旧的机器去掉,影响的也是一小部分的数据。这样看似比较完美了,,但假如其中一个节点B数据激增,挂了,所有数据会倒到C---C也扛不住了----所有数据会倒到D ……以此类推,最终全挂了!整个世界清静了!!!
显然,这种方式因为数据的不平均导致服务挂了。所以我们的一致性hash还需要具有平衡性。
为解决平衡性,一致性hash引入了虚拟节点”的概念。“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。这样我们如果有25台服务器,每台虚拟成10个,就有250个虚拟节点。这样就保证了每个节点的负载不会太大,压力均摊,有事大家一起扛!!!
先写这么多吧,重头看了一遍,乱的一笔。大家有时间都可以编辑补充吧,,,文中部分图片代码忘了记下出处。知乎ID:PeterHall


